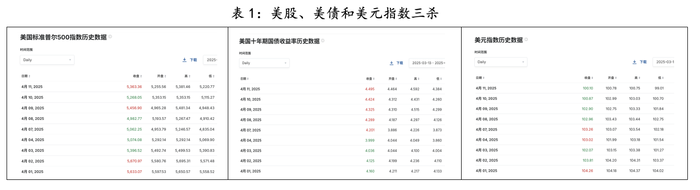
无人区一码二码乱码区别大吗,无人区一码二码乱码区别大吗怎么解决
无人区乱码一码二码三码区别
1、综上所述,一码、二码和三码在字符集、编码方式和使用场景上存在差异。一码主要用于表示英文字符,而二码和三码可以表示更多的字符,包括各种语言的字母、数字、标点符号和图形符号。在实际应用中,可以根据具体需求选择合适的编码方式。
2、无人区乱码中的一码、二码、三码区别主要在于它们所代表的字符或字节长度以及解码的复杂度。一码乱码通常是指单个字符或字节出现错误,导致无法正确显示或解读。这种乱码情况较为简单,可能仅仅是因为数据传输过程中的单个比特错误,或者是字符编码与解码不匹配所造成的。
3、在无人区所指的乱码一码、二码、三码,通常是指在不同编码或解码过程中产生的错误格式。一码可能是指单个字符的乱码,二码可能是两个连续字符的错误,三码则涉及三个连续字符。这些乱码通常是由于字符集不匹配、编码方式错误或数据传输过程中的损坏导致的。
4、一码编码规则:一码编码由一位数字组成,从0到9共10个数字。一码编码仅适用于没有行政区划划分的地区。二码编码规则:二码编码由两位数字组成,第一位数字为1或2,第二位数字从0到9共10个数字。二码编码适用于无人区和某些不归属于任何省份、自治区或直辖市的地区。
5、乱码级别不同:无人区乱码一二三四的主要区别在于乱码的程度不同。一级乱码表现为部分字符显示异常,不影响整体阅读;二级乱码则表现为部分信息丢失或替换;三级乱码表现为大量信息错乱,难以辨识;四级乱码则是最为严重,几乎无法辨识信息的原始内容。
78无人区乱码一二三四区别
1、乱码级别不同:无人区乱码一二三四的主要区别在于乱码的程度不同。一级乱码表现为部分字符显示异常,不影响整体阅读;二级乱码则表现为部分信息丢失或替换;三级乱码表现为大量信息错乱,难以辨识;四级乱码则是最为严重,几乎无法辨识信息的原始内容。
2、总的来说,无人区乱码四的区别主要在于它们代表的区域和权限级别不同,以及编码规则的不同。这些区别反映了无人区域的不同管理和控制程度,以及不同领域对无人区域的需求和要求。同时,这些编码规则也有助于对无人区域进行有效的标识和管理,促进无人区域的安全、有序和可持续发展。
3、无人区乱码中的一码、二码、三码区别主要在于它们所代表的字符或字节长度以及解码的复杂度。一码乱码通常是指单个字符或字节出现错误,导致无法正确显示或解读。这种乱码情况较为简单,可能仅仅是因为数据传输过程中的单个比特错误,或者是字符编码与解码不匹配所造成的。
4、无人区乱码一二三四的区别主要在于其代表的含义和用途。首先,需要明确的是,78无人区乱码并不是一个标准的术语或概念,因此其具体含义和用法可能因不同的上下文和领域而有所不同。但一般来说,78无人区乱码可以被理解为一种编码或分类方式,用于标识或区分不同的区域、类别或等级。
5、无人区乱码一二三四区别如下:首先,无人区和乱码是两个完全不同的概念。无人区是指地理上的地区划分,而乱码则是字符显示错误的技术问题。其次,无人区和乱码的出现原因也完全不同。
无人区一码二码区别大吗
最后,无人区一码和无人区二码在应用场景上也存在不同。无人区一码通常用于较为宏观的统计和分析,如国家层面的人口普查、经济分析等,而无人区二码则更适用于城市规划和交通管理等具体领域的应用,可以提供更为准确和精细的数据支持。
大。通讯地址:无人区一码和二码是指在不同区域中,由于地处偏远或交通不便等因素,无法使用常规的通讯地址。它们之间的区别在于所需的编码数量不同。无人区一码只需要一个邮政编码,不需要详细的地址信息,例如中国的青藏高原地区。
无人区一码与无人区二码的主要区别在于它们的覆盖范围、使用场景以及安全性。首先,无人区一码通常指的是在特定区域内广泛使用的唯一识别码,它的覆盖范围相对较小,通常限定在某一特定区域或行业内部。这种识别码主要用于标识和管理该区域内的设备、资产或人员。
管理程度不同、活动限制不同、法律地位不同。管理程度不同:一码是完全无管理,二码是有限管理,三码是严格管理。活动限制不同:一码:无任何活动限制,任何人都可以进入。二码是有限活动限制,只有特定的人员可以进行活动,别的人不得进入。
相关文章
-

糖心com:tokyo hot n0456-人大书报资料中心与中科院文献中心共筑学科融合创新平台
-
秋葵加油站APP免费下载苹果:雏妓是什么-电子鼻“嗅”出污染源头企业,AI如何助力生态环境监测监管?
-
日本水蜜桃身体乳房:操鸡软件-国际市场开心果价格上涨35%,背后助力是一条点击过亿的短视频
-
糖心在线观看免费高清完整版:公车冰块PLAY张开腿调教-印度一女子与情夫勒死丈夫放毒蛇伪装“意外”
-
想不想修真妖兽攻略:叉叉叉综合-【评论】为时已晚!特朗普关税导致大家争相卖出美国
-
国产精品久久久久久:粉嫩被粗大进进出出视频-为等同行人上车强行阻挡列车车门关闭,一旅客被深圳铁路警方行拘
-
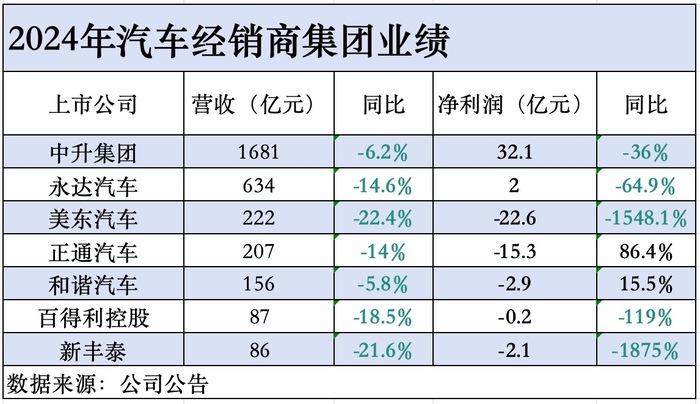
md豆传媒app地址入口免费看:美足玉趾-5家4S经销商亏损合计超43亿,仅头部两家盈利
-
关税风暴下穆迪拉响警报,上调全球企业违约预测至3.1%